
AI is unquestionably a powerful tool that can expedite work and increase efficiency in many industries, but it’s well known to have some serious drawbacks, such as algorithmic bias.
Noah Giansiracusa, Associate Professor of Mathematics and Data Science at Bentley University, Boston, US, and the author of the book How Algorithms Create and Prevent Fake News, considers AI in the context of retail finance.
Noah evaluates what algorithmic bias means in the retail finance setting, why it crops up so persistently—and how companies can use AI in positive ways that reduce the risk of discrimination and other undesirable outcomes.

Supervised learning
Let’s start with supervised learning, the backbone of all modern AI, including the generative AI that has swept the world by storm.
The basic setup for supervised learning is that there is a variable of interest, referred to as the “target”, values of which we would like to predict based on the values of a collection of variables called “predictors”.
We presume that we have a collection of data points, the “training data”, for which the values of the predictors and the target are known – and the goal of supervised learning is to uncover a relationship between the predictors and the target.
Once the relationship between the predictors and the target is established, we can use it to make predictions. And so, for a new data point, with known predictor values but an unknown target value, the relationship deduced from the training data is used to estimate the value of the target.
This being a very general and abstract description, let’s make this concept more concrete by considering an example in retail finance.
AI in retail finance
Our proposed scenario is that a bank wants to use supervised learning to automate the process of deciding which customers to grant small business loans to.
In the past, the bank recorded three things about each loan request: the amount of the loan request, a numerical score denoting how favorably a loan officer at the bank viewed the business proposal, and whether the loan was successfully paid back on time.
We use these historical records to form our training data: the request amount and proposal score are the two predictors, and the target is a binary variable with, say, “O”, indicating the loan was paid back on time and “X” indicating that the loan wasn’t paid back. In this case, the training data can be visualized with a scatterplot:
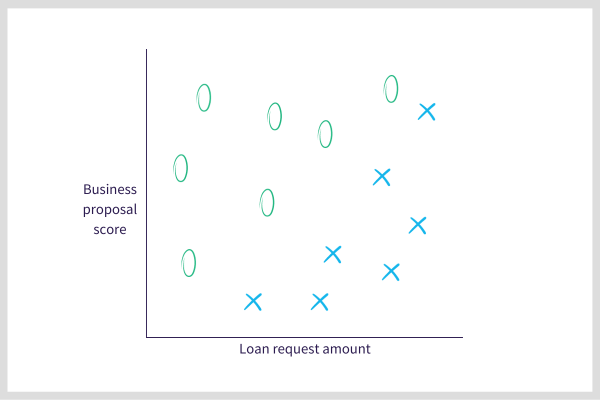
It’s easy to see that there’s an invisible diagonal line dividing the successfully repaid loans from the unsuccessful ones. We can draw that line and call that our “model”.
When a new loan request comes in, we simply plot it as a point in the above map and see which side of the diagonal line it falls on. That tells us whether our model predicts the new loan will be successfully repaid or not, and so the bank can use that prediction to decide whether to grant the loan – or not.
In real life, the patterns in the data are much more complex and many predictors are used, which means visualization is no longer an option.
And that’s where supervised learning comes in. Supervised learning is a collection of elaborate mathematical methods for doing what we just did by hand (drawing a diagonal line) – but in much more complicated and higher-dimensional settings.
Yet the basic idea is quite similar to the scatter diagram above: we find a shape to represent our data points, use this shape to separate successful loans from unsuccessful ones based on historical data and then predict the success of new loan requests by seeing which side of the shape they fall into.
Algorithmic Bias
Where does bias come into this story?
The answer is the training data.
Due to unfortunate human biases, women and other members of underrepresented populations face more hurdles in their efforts to successfully launch a business. This could include challenges such as more difficulty attracting customers and investors than their majority member counterparts. Consequently, their loan repayment rates are likely to be lower.
Now imagine that among our loan approval model’s predictors are some demographic variables, like race and gender—or even just variables that correlate with these variables, for instance, postcode (which often correlates with race) and prior employment (which has some correlation with gender).
When the model uses these predictors, due to the bias mentioned above, it will see that certain neighborhoods and careers have lower loan repayment rates, and those will be neighborhoods with more racial minorities and careers with more women.
Once banks use biased predictive models to make loan decisions, this creates data of women and minorities getting loans rejected at higher rates
Noah Giansiracusa, Bentley University
Then when a new bank customer arrives and requests a loan, if they are from a neighborhood that veers non-white or a career that veers less male, the chance of the model predicting successful loan repayment will be lower than it otherwise would. Thus, the model has absorbed bias in the business world and is now causing discriminatory behavior in loan approvals.
Unfortunately, left unchecked, these problems tend to cascade. Once banks use biased predictive models to make loan decisions, this creates data of women and minorities getting loans rejected at higher rates—and this data may become training data for other predictive models in retail finance.
Bias often spreads in this manner—biased data trains one model that then produces further biased data that then trains more models creating even more discrimination and even more biased data.
Moreover, this use of predictive models tends to lock us in the past: even if society makes progress in treating all people equally, if predictive models are trained on prior data the models will behave like the past, not the present.
How to avoid bias in machine learning?
There is no easy, silver-bullet cure for bias in machine learning.
Careful analysis and selection of training data can help, along with routine audits of predictive models to inspect for biased outcomes is essential.
It’s important to recognize that machine learning and AI come in many ‘flavors’ and can be used in many different ways, some of which are less prone to bias.
For instance, a recent Nature article found that AI can help find suspect citations on Wikipedia and suggest potentially better ones that moderators can inspect and manually select if desired.
This is an excellent example of AI being used as a tool to assist human decision-making, rather than replacing it.
Use AI to collect information and inform your decisions
In general, using AI to help gather information and inform decisions is less risky than using AI to make decisions—particularly since AI decisions tend to be inscrutable and prone to bias, as discussed earlier.
What might this look like in retail finance?
One of Recordsure’s tasks is inspecting the quality of advice between a human financial adviser and their customer, by evaluating the various paperwork and audio recordings of the meetings, to make sure all necessary information was captured and conveyed in a manner that adheres to regulatory and organizational compliance standards.
In a similar spirit as the Wikipedia application mentioned above, Recordsure uses AI to hunt out the relevant information required for presentation to a human who is doing a manual ‘file review’. And the AI recommends which customer advice cases should be reviewed by a human.
Because there is still significant room for bias in these uses of AI, the model inspections and vigilance mentioned earlier are a certain necessity.
The good news is that the risks are far lower with this ‘human-in-the-loop’ approach than a fully automated one.
About the author
Noah Giansiracusa (PhD in math, Brown University) is a tenured Associate Professor of Math and Data Science at Bentley University, a business school near Boston. His research interests range from algebraic geometry to machine learning to empirical legal studies.
After publishing the book How Algorithms Create and Prevent Fake News in July 2021, Noah has gotten more involved in public writing/speaking and policy discussions concerning data-driven algorithms and their role in society.
He’s appeared on cable TV and BBC radio, written op-eds for Scientific American, TIME, Barron’s, Boston Globe, Wired, Slate, and Fast Company, and been quoted in a range of newspapers. Noah is currently working on a second book, a popular math book forthcoming with Riverhead Books (an imprint of Penguin).



