
Scale up file review provisions without increasing costs
CASE STUDY Consultancy Managed Services UK

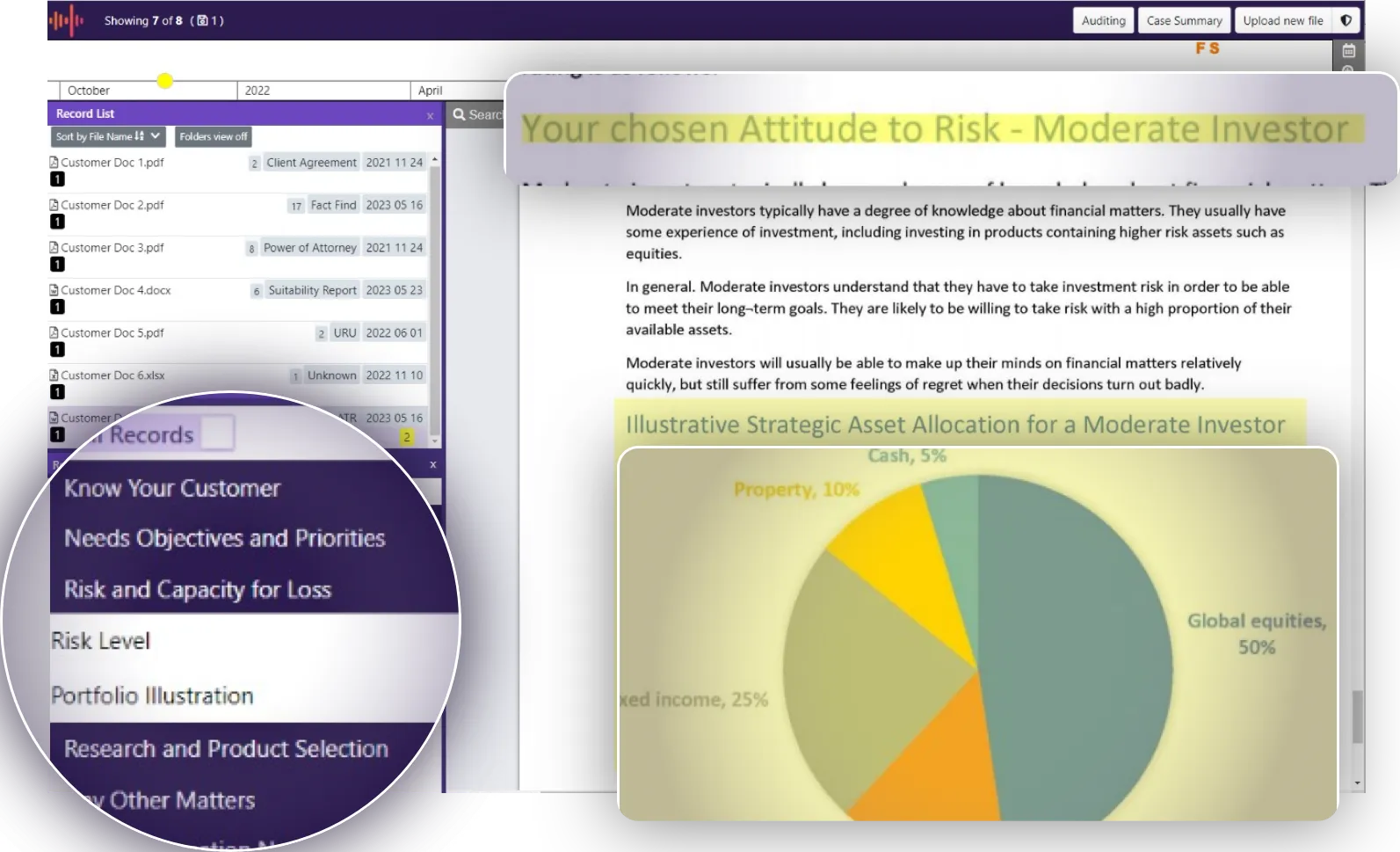
CASE STUDY Consultancy Managed Services UK

CASE STUDY Big 4 Consultancy Firm Australia

Recordsure partners with Iress to deliver a unique AI

The FCA recently released new findings into its review